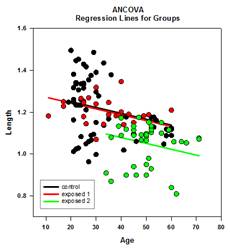
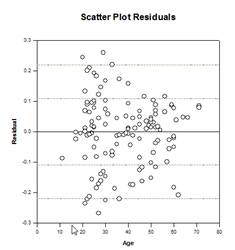
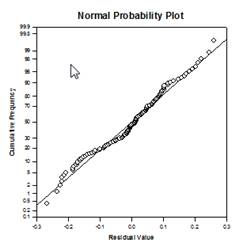
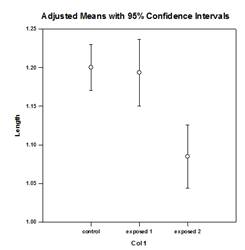
تحسينات المقارنة المتعددة – تم إجراء تحسن كبير في حساب القيمة P للمقارنة المتعددة. إجراءات المقارنة المتعددة التالية، Tukey (الاختبارات غير البارامترية)، SNK (الاختبارات غير البارامترية)، Dunnett’s، Dunn’s (غير البارامترية فقط)، وDuncan لم تحسب القيم الاحتمالية تحليليًا، ولكنها استخدمت بدلاً من ذلك جداول بحث للقيم الحرجة لتوزيع معين لتحديد، باستخدام الاستيفاء إذا لزم الأمر، ما إذا كانت إحصائية الاختبار المحسوبة تمثل فرقًا كبيرًا في متوسطات المجموعة. وبالتالي، لم يتم الإبلاغ عن القيم p لهذه الاختبارات، ولكن تم فقط استنتاج ما إذا كان هناك فرق كبير أم لا. إحدى المشاكل الرئيسية في هذا الأسلوب هي أن جداول البحث متاحة فقط لمستويين من الأهمية، .05 و.01. مشكلة أخرى هي أن العديد من العملاء يريدون معرفة القيم الاحتمالية. بالنسبة لـ SigmaPlot، تم ترميز الخوارزميات لحساب توزيعات إحصائيات الاختبار لجميع الإجراءات اللاحقة، مما يجعل جداول البحث قديمة. ونتيجة لذلك، يتم الآن وضع القيم الاحتمالية المعدلة لجميع الإجراءات اللاحقة في التقرير. وأيضًا، لم تعد هناك حاجة لتقييد مستوى أهمية المقارنات المتعددة بـ .05 أو .01. وبدلاً من ذلك، سيكون مستوى أهمية المقارنات المتعددة هو نفس مستوى أهمية الاختبار الرئيسي (الجامع). لا يوجد أي قيود على هذه القيمة P – يمكن استخدام أي قيمة صالحة.
معيار معلومات Akaike (AICc) – تمت إضافة معيار معلومات Akaike إلى تقارير معالج الانحدار ومعالج التوافق الديناميكي ومربع حوار خيارات التقرير. فهو يوفر طريقة لقياس الأداء النسبي في ملاءمة نموذج الانحدار لمجموعة معينة من البيانات. يعتمد المعيار على مفهوم إنتروبيا المعلومات ، ويقدم قياسًا نسبيًا للمعلومات المفقودة عند استخدام نموذج لوصف البيانات.
وبشكل أكثر تحديدًا، فإنه يعطي مقايضة بين تعظيم احتمالية النموذج المقدر (مثل تقليل مجموع المربعات المتبقية إذا كانت البيانات موزعة بشكل طبيعي) والحفاظ على عدد المعلمات الحرة في النموذج إلى الحد الأدنى، مما يقلل من تعقيده. على الرغم من أن جودة الملاءمة يتم تحسينها دائمًا تقريبًا عن طريق إضافة المزيد من المعلمات، إلا أن التجاوز سيزيد من حساسية النموذج للتغيرات في البيانات المدخلة ويمكن أن يدمر قدرته التنبؤية.
السبب الأساسي لاستخدام AIC هو كدليل لاختيار النموذج. ومن الناحية العملية، يتم حسابها لمجموعة من النماذج المرشحة ومجموعة بيانات معينة. يتم تحديد النموذج ذو أصغر قيمة لـ AIC باعتباره النموذج في المجموعة الذي يمثل النموذج “الحقيقي” على أفضل وجه، أو النموذج الذي يقلل من فقدان المعلومات، وهو ما تم تصميم AIC لتقديره.
بعد تحديد النموذج الذي يحتوي على الحد الأدنى من AIC، يمكن أيضًا حساب الاحتمالية النسبية لكل نموذج من النماذج المرشحة الأخرى لقياس احتمال تقليل فقدان المعلومات مقارنة بالنموذج الذي يحتوي على الحد الأدنى من AIC. يمكن أن يساعد الاحتمال النسبي المحقق في تحديد ما إذا كان ينبغي الاحتفاظ بأكثر من نموذج واحد في المجموعة لمزيد من الدراسة.
يعتمد حساب AIC على الصيغة العامة التالية التي تم الحصول عليها بواسطة Akaike 1
 أين
أين هو عدد المعلمات الحرة في النموذج و
هو عدد المعلمات الحرة في النموذج و هي القيمة القصوى لدالة الاحتمالية للنموذج المقدر.
عندما يكون حجم العينة من البيانات
هي القيمة القصوى لدالة الاحتمالية للنموذج المقدر.
عندما يكون حجم العينة من البيانات صغير بالنسبة لعدد المعلمات (يقول بعض المؤلفين متى ليست أكثر من عدة مرات أكبر من
صغير بالنسبة لعدد المعلمات (يقول بعض المؤلفين متى ليست أكثر من عدة مرات أكبر من )، لن تعمل AIC بشكل جيد للحماية من التجهيز الزائد. في هذه الحالة، هناك نسخة مصححة من AIC مقدمة بواسطة:
)، لن تعمل AIC بشكل جيد للحماية من التجهيز الزائد. في هذه الحالة، هناك نسخة مصححة من AIC مقدمة بواسطة:
 يتبين أن AICc يفرض عقوبة أكبر من AIC عندما تكون هناك معلمات إضافية. يبدو أن معظم المؤلفين متفقون على ضرورة استخدام AICc بدلاً من AIC في جميع المواقف.
وظائف الاحتمالية الملائمة – تمت إضافة 24 وظيفة جديدة للاحتمالية إلى معيار المكتبة الملائمة.jfl. هذه الوظائف وبعض المعادلات والأشكال الرسومية مبينة أدناه:
يتبين أن AICc يفرض عقوبة أكبر من AIC عندما تكون هناك معلمات إضافية. يبدو أن معظم المؤلفين متفقون على ضرورة استخدام AICc بدلاً من AIC في جميع المواقف.
وظائف الاحتمالية الملائمة – تمت إضافة 24 وظيفة جديدة للاحتمالية إلى معيار المكتبة الملائمة.jfl. هذه الوظائف وبعض المعادلات والأشكال الرسومية مبينة أدناه:
 على سبيل المثال، يحتوي الملف المناسب لوظيفة الكثافة اللوغاريتمية الطبيعية على معادلة الكثافة اللوغاريتمية الطبيعية lognormden(x,a,b)، ومعادلات لتقدير المعلمة الأولية التلقائية ووظائف الترجيح السبع الجديدة.
[Variables]
س = العمود (1)
ص = العمود (2)
reciprocal_y = 1/abs(y)
reciprocal_ysquare = 1/y^2
reciprocal_x = 1/أبس(س)
reciprocal_xsquare = 1/x^2
reciprocal_pred = 1/أبس(و)
reciprocal_predsqr = 1/f^2
الوزن_كوشي = 1/(1+4*(yf)^2)
‘وظائف تقدير المعلمة الأولية التلقائية
فخ(ف,ص)=.5*المجموع(({0,q}+{q,0})[data(2,size(q))] *فرق (ص)[data(2,size(r))] )
الصورة = فرز (معقد (س، ص)، س)
u = كتلة فرعية(s,1,1,1, size(x))
v = كتلة فرعية(s,2,1,2, size(y))
أعني = فخ (u*v،u)
varest=فخ((u-الأسوء)^2*v,u)
ع = 1 + أفاريست / أتعس ^ 2
[Parameters]
أ= إذا (أعني> 0, قانون الجنسية (يعني/جذر(ع)), 0)
ب = إذا (ص> = 1، الجذر التربيعي (ln(p)))، 1)
[Equation]
f=lognormden(x,a,b)
تناسب f إلى y
”تناسب f إلى y مع الوزن المتبادل_y
”تناسب f إلى y مع الوزن reciprocal_ysquare
”تناسب f إلى y مع الوزن reciprocal_x
”تناسب f إلى y مع الوزن reciprocal_xsquare
”تناسب f إلى y مع الوزن المتبادل
”تناسب f إلى y مع الوزن reciprocal_predsqr
”تناسب f إلى y مع الوزن Weight_Cauchy
[Constraints]
ب> 0
[Options]
التسامح = 1e-010
حجم الخطوات = 1
التكرارات = 200
وظائف الوزن في الانحدار غير الخطي – تستخدم عناصر معادلة SigmaPlot أحيانًا متغير وزن بغرض تعيين وزن لكل ملاحظة (أو استجابة) في مجموعة بيانات الانحدار. يقيس وزن الملاحظة عدم اليقين بالنسبة للتوزيع الاحتمالي الذي تم أخذ العينات منه. يشير الوزن الأكبر إلى ملاحظة تختلف قليلًا عن المتوسط الحقيقي لتوزيعها بينما يشير الوزن الأصغر إلى ملاحظة تم أخذ عينات منها أكثر من ذيل توزيعها.
في ظل الافتراضات الإحصائية لتقدير معلمات النموذج المناسب باستخدام نهج المربعات الصغرى، تكون الأوزان، حتى عامل القياس، مساوية لمقلوب التباينات السكانية للتوزيعات (الغاوسية) التي تم أخذ عينات منها الملاحظات. هنا، نحدد المتبقي ، والذي يسمى أحيانًا الخام المتبقي ، على أنه الفرق بين الملاحظة والقيمة المتوقعة (قيمة النموذج المناسب) عند قيمة معينة للمتغير (المتغيرات) المستقل. إذا كانت تباينات الملاحظات ليست كلها متماثلة ( تغايرية) ، فستكون هناك حاجة إلى متغير وزن ويتم حل مشكلة المربعات الصغرى الموزونة لتقليل المجموع المرجح لمربعات البقايا للعثور على أفضل المعلمات المناسبة.
ستسمح ميزتنا الجديدة للمستخدم بتحديد متغير الوزن كدالة للمعلمات الموجودة في النموذج المناسب. تمت إضافة سبع وظائف وزن محددة مسبقًا إلى كل وظيفة مناسبة (تختلف الوظائف ثلاثية الأبعاد قليلاً). السبعة الموضحة أدناه هي 1/y، 1/y 2 ، 1/x، 1/x 2 ، 1/متوقع، 1/متنبأ 2 وكوشي.
على سبيل المثال، يحتوي الملف المناسب لوظيفة الكثافة اللوغاريتمية الطبيعية على معادلة الكثافة اللوغاريتمية الطبيعية lognormden(x,a,b)، ومعادلات لتقدير المعلمة الأولية التلقائية ووظائف الترجيح السبع الجديدة.
[Variables]
س = العمود (1)
ص = العمود (2)
reciprocal_y = 1/abs(y)
reciprocal_ysquare = 1/y^2
reciprocal_x = 1/أبس(س)
reciprocal_xsquare = 1/x^2
reciprocal_pred = 1/أبس(و)
reciprocal_predsqr = 1/f^2
الوزن_كوشي = 1/(1+4*(yf)^2)
‘وظائف تقدير المعلمة الأولية التلقائية
فخ(ف,ص)=.5*المجموع(({0,q}+{q,0})[data(2,size(q))] *فرق (ص)[data(2,size(r))] )
الصورة = فرز (معقد (س، ص)، س)
u = كتلة فرعية(s,1,1,1, size(x))
v = كتلة فرعية(s,2,1,2, size(y))
أعني = فخ (u*v،u)
varest=فخ((u-الأسوء)^2*v,u)
ع = 1 + أفاريست / أتعس ^ 2
[Parameters]
أ= إذا (أعني> 0, قانون الجنسية (يعني/جذر(ع)), 0)
ب = إذا (ص> = 1، الجذر التربيعي (ln(p)))، 1)
[Equation]
f=lognormden(x,a,b)
تناسب f إلى y
”تناسب f إلى y مع الوزن المتبادل_y
”تناسب f إلى y مع الوزن reciprocal_ysquare
”تناسب f إلى y مع الوزن reciprocal_x
”تناسب f إلى y مع الوزن reciprocal_xsquare
”تناسب f إلى y مع الوزن المتبادل
”تناسب f إلى y مع الوزن reciprocal_predsqr
”تناسب f إلى y مع الوزن Weight_Cauchy
[Constraints]
ب> 0
[Options]
التسامح = 1e-010
حجم الخطوات = 1
التكرارات = 200
وظائف الوزن في الانحدار غير الخطي – تستخدم عناصر معادلة SigmaPlot أحيانًا متغير وزن بغرض تعيين وزن لكل ملاحظة (أو استجابة) في مجموعة بيانات الانحدار. يقيس وزن الملاحظة عدم اليقين بالنسبة للتوزيع الاحتمالي الذي تم أخذ العينات منه. يشير الوزن الأكبر إلى ملاحظة تختلف قليلًا عن المتوسط الحقيقي لتوزيعها بينما يشير الوزن الأصغر إلى ملاحظة تم أخذ عينات منها أكثر من ذيل توزيعها.
في ظل الافتراضات الإحصائية لتقدير معلمات النموذج المناسب باستخدام نهج المربعات الصغرى، تكون الأوزان، حتى عامل القياس، مساوية لمقلوب التباينات السكانية للتوزيعات (الغاوسية) التي تم أخذ عينات منها الملاحظات. هنا، نحدد المتبقي ، والذي يسمى أحيانًا الخام المتبقي ، على أنه الفرق بين الملاحظة والقيمة المتوقعة (قيمة النموذج المناسب) عند قيمة معينة للمتغير (المتغيرات) المستقل. إذا كانت تباينات الملاحظات ليست كلها متماثلة ( تغايرية) ، فستكون هناك حاجة إلى متغير وزن ويتم حل مشكلة المربعات الصغرى الموزونة لتقليل المجموع المرجح لمربعات البقايا للعثور على أفضل المعلمات المناسبة.
ستسمح ميزتنا الجديدة للمستخدم بتحديد متغير الوزن كدالة للمعلمات الموجودة في النموذج المناسب. تمت إضافة سبع وظائف وزن محددة مسبقًا إلى كل وظيفة مناسبة (تختلف الوظائف ثلاثية الأبعاد قليلاً). السبعة الموضحة أدناه هي 1/y، 1/y 2 ، 1/x، 1/x 2 ، 1/متوقع، 1/متنبأ 2 وكوشي.
 أحد تطبيقات هذا الترجيح التكيفي الأكثر عمومية هو في المواقف التي لا يمكن فيها تحديد تباينات الملاحظات قبل إجراء الملاءمة. على سبيل المثال، إذا كانت جميع الملاحظات موزعة بواسون، فإن متوسط عدد السكان، وهو ما تقدره القيم المتوقعة، يساوي تباينات المجتمع. على الرغم من أن أسلوب المربعات الصغرى لتقدير المعلمات مصمم للبيانات الموزعة بشكل طبيعي، إلا أنه يتم استخدام توزيعات أخرى أحيانًا مع المربعات الصغرى عندما لا تتوفر طرق أخرى. في حالة بيانات بواسون ، نحتاج إلى تعريف متغير الوزن باعتباره مقلوب القيم المتوقعة. يُشار إلى هذا الإجراء أحيانًا باسم “الترجيح بالقيم المتوقعة”.
تطبيق آخر للترجيح التكيفي هو الحصول على إجراءات قوية لتقدير المعلمات التي تخفف من آثار القيم المتطرفة. في بعض الأحيان، قد يكون هناك عدد قليل من الملاحظات في مجموعة البيانات التي يتم أخذ عينات منها من ذيل توزيعاتها باحتمالية صغيرة، أو هناك عدد قليل من الملاحظات التي يتم أخذ عينات منها من توزيعات تنحرف قليلاً عن افتراض الحالة الطبيعية المستخدم في تقدير المربعات الصغرى وبالتالي تلوث مجموعة البيانات. هذه الملاحظات الشاذة، والتي تسمى القيم المتطرفة في متغير الاستجابة ، يمكن أن يكون لها تأثير كبير على نتائج الملاءمة لأنها تحتوي على بقايا كبيرة نسبيًا (خام أو مرجح) وبالتالي تضخم مجموع المربعات التي يتم تقليلها.
تتمثل إحدى طرق التخفيف من آثار القيم المتطرفة في استخدام متغير الوزن الذي يمثل دالة للقيم المتبقية (وبالتالي، أيضًا وظيفة للمعلمات)، حيث يرتبط الوزن المخصص للملاحظة عكسيًا بحجم المتبقي. يعتمد تعريف وظيفة الترجيح المستخدمة على افتراضات حول توزيعات الملاحظات (بافتراض أنها ليست طبيعية) ومخطط لتحديد حجم المتبقي الذي يجب تحمله. يتم تعريف دالة الترجيح كوشي من حيث القيم المتبقية، yf حيث y هي قيمة المتغير التابع وf هي الدالة الملائمة، ويمكن استخدامها لتقليل تأثير القيم المتطرفة.
الوزن_كوشي = 1/(1+4*(yf)^2)
تعتمد خوارزمية تقدير المعلمة التي نستخدمها للترجيح التكيفي، والمربعات الصغرى المعاد وزنها بشكل متكرر (IRLS)، على حل سلسلة من مشاكل المربعات الصغرى ذات الوزن الثابت حيث يتم حل كل مشكلة فرعية باستخدام تطبيقنا الحالي لخوارزمية Levenberg-Marquardt . تبدأ هذه العملية بتقييم الأوزان باستخدام قيم المعلمات الأولية ثم تقليل مجموع المربعات بهذه الأوزان الثابتة. يتم بعد ذلك استخدام المعلمات الأكثر ملائمة لإعادة تقييم الأوزان.
باستخدام قيم الوزن الجديدة، يتم تكرار العملية المذكورة أعلاه لتقليل مجموع المربعات. ونستمر على هذا المنوال حتى يتحقق التقارب. المعيار المستخدم للتقارب هو أن يكون الخطأ النسبي بين الجذر التربيعي لمجموع البقايا المرجحة لقيم المعلمات الحالية والجذر التربيعي لمجموع البقايا المرجحة لقيم معلمات التكرار السابق أقل من قيمة التسامح المنصوص عليها في عنصر المعادلة. وكما هو الحال مع إجراءات التقدير الأخرى، فإن التقارب غير مضمون.
أحد تطبيقات هذا الترجيح التكيفي الأكثر عمومية هو في المواقف التي لا يمكن فيها تحديد تباينات الملاحظات قبل إجراء الملاءمة. على سبيل المثال، إذا كانت جميع الملاحظات موزعة بواسون، فإن متوسط عدد السكان، وهو ما تقدره القيم المتوقعة، يساوي تباينات المجتمع. على الرغم من أن أسلوب المربعات الصغرى لتقدير المعلمات مصمم للبيانات الموزعة بشكل طبيعي، إلا أنه يتم استخدام توزيعات أخرى أحيانًا مع المربعات الصغرى عندما لا تتوفر طرق أخرى. في حالة بيانات بواسون ، نحتاج إلى تعريف متغير الوزن باعتباره مقلوب القيم المتوقعة. يُشار إلى هذا الإجراء أحيانًا باسم “الترجيح بالقيم المتوقعة”.
تطبيق آخر للترجيح التكيفي هو الحصول على إجراءات قوية لتقدير المعلمات التي تخفف من آثار القيم المتطرفة. في بعض الأحيان، قد يكون هناك عدد قليل من الملاحظات في مجموعة البيانات التي يتم أخذ عينات منها من ذيل توزيعاتها باحتمالية صغيرة، أو هناك عدد قليل من الملاحظات التي يتم أخذ عينات منها من توزيعات تنحرف قليلاً عن افتراض الحالة الطبيعية المستخدم في تقدير المربعات الصغرى وبالتالي تلوث مجموعة البيانات. هذه الملاحظات الشاذة، والتي تسمى القيم المتطرفة في متغير الاستجابة ، يمكن أن يكون لها تأثير كبير على نتائج الملاءمة لأنها تحتوي على بقايا كبيرة نسبيًا (خام أو مرجح) وبالتالي تضخم مجموع المربعات التي يتم تقليلها.
تتمثل إحدى طرق التخفيف من آثار القيم المتطرفة في استخدام متغير الوزن الذي يمثل دالة للقيم المتبقية (وبالتالي، أيضًا وظيفة للمعلمات)، حيث يرتبط الوزن المخصص للملاحظة عكسيًا بحجم المتبقي. يعتمد تعريف وظيفة الترجيح المستخدمة على افتراضات حول توزيعات الملاحظات (بافتراض أنها ليست طبيعية) ومخطط لتحديد حجم المتبقي الذي يجب تحمله. يتم تعريف دالة الترجيح كوشي من حيث القيم المتبقية، yf حيث y هي قيمة المتغير التابع وf هي الدالة الملائمة، ويمكن استخدامها لتقليل تأثير القيم المتطرفة.
الوزن_كوشي = 1/(1+4*(yf)^2)
تعتمد خوارزمية تقدير المعلمة التي نستخدمها للترجيح التكيفي، والمربعات الصغرى المعاد وزنها بشكل متكرر (IRLS)، على حل سلسلة من مشاكل المربعات الصغرى ذات الوزن الثابت حيث يتم حل كل مشكلة فرعية باستخدام تطبيقنا الحالي لخوارزمية Levenberg-Marquardt . تبدأ هذه العملية بتقييم الأوزان باستخدام قيم المعلمات الأولية ثم تقليل مجموع المربعات بهذه الأوزان الثابتة. يتم بعد ذلك استخدام المعلمات الأكثر ملائمة لإعادة تقييم الأوزان.
باستخدام قيم الوزن الجديدة، يتم تكرار العملية المذكورة أعلاه لتقليل مجموع المربعات. ونستمر على هذا المنوال حتى يتحقق التقارب. المعيار المستخدم للتقارب هو أن يكون الخطأ النسبي بين الجذر التربيعي لمجموع البقايا المرجحة لقيم المعلمات الحالية والجذر التربيعي لمجموع البقايا المرجحة لقيم معلمات التكرار السابق أقل من قيمة التسامح المنصوص عليها في عنصر المعادلة. وكما هو الحال مع إجراءات التقدير الأخرى، فإن التقارب غير مضمون.
 على سبيل المثال، يحتوي الملف المناسب لوظيفة الكثافة اللوغاريتمية الطبيعية على معادلة الكثافة اللوغاريتمية الطبيعية lognormden(x,a,b)، ومعادلات لتقدير المعلمة الأولية التلقائية ووظائف الترجيح السبع الجديدة.
[Variables]
س = العمود (1)
ص = العمود (2)
reciprocal_y = 1/abs(y)
reciprocal_ysquare = 1/y^2
reciprocal_x = 1/أبس(س)
reciprocal_xsquare = 1/x^2
reciprocal_pred = 1/أبس(و)
reciprocal_predsqr = 1/f^2
الوزن_كوشي = 1/(1+4*(yf)^2)
‘وظائف تقدير المعلمة الأولية التلقائية
فخ(ف,ص)=.5*المجموع(({0,q}+{q,0})[data(2,size(q))] *فرق (ص)[data(2,size(r))] )
الصورة = فرز (معقد (س، ص)، س)
u = كتلة فرعية(s,1,1,1, size(x))
v = كتلة فرعية(s,2,1,2, size(y))
أعني = فخ (u*v،u)
varest=فخ((u-الأسوء)^2*v,u)
ع = 1 + أفاريست / أتعس ^ 2
[Parameters]
أ= إذا (أعني> 0, قانون الجنسية (يعني/جذر(ع)), 0)
ب = إذا (ص> = 1، الجذر التربيعي (ln(p)))، 1)
[Equation]
f=lognormden(x,a,b)
تناسب f إلى y
”تناسب f إلى y مع الوزن المتبادل_y
”تناسب f إلى y مع الوزن reciprocal_ysquare
”تناسب f إلى y مع الوزن reciprocal_x
”تناسب f إلى y مع الوزن reciprocal_xsquare
”تناسب f إلى y مع الوزن المتبادل
”تناسب f إلى y مع الوزن reciprocal_predsqr
”تناسب f إلى y مع الوزن Weight_Cauchy
[Constraints]
ب> 0
[Options]
التسامح = 1e-010
حجم الخطوات = 1
التكرارات = 200
وظائف الوزن في الانحدار غير الخطي – تستخدم عناصر معادلة SigmaPlot أحيانًا متغير وزن بغرض تعيين وزن لكل ملاحظة (أو استجابة) في مجموعة بيانات الانحدار. يقيس وزن الملاحظة عدم اليقين بالنسبة للتوزيع الاحتمالي الذي تم أخذ العينات منه. يشير الوزن الأكبر إلى ملاحظة تختلف قليلًا عن المتوسط الحقيقي لتوزيعها بينما يشير الوزن الأصغر إلى ملاحظة تم أخذ عينات منها أكثر من ذيل توزيعها.
في ظل الافتراضات الإحصائية لتقدير معلمات النموذج المناسب باستخدام نهج المربعات الصغرى، تكون الأوزان، حتى عامل القياس، مساوية لمقلوب التباينات السكانية للتوزيعات (الغاوسية) التي تم أخذ عينات منها الملاحظات. هنا، نحدد المتبقي ، والذي يسمى أحيانًا الخام المتبقي ، على أنه الفرق بين الملاحظة والقيمة المتوقعة (قيمة النموذج المناسب) عند قيمة معينة للمتغير (المتغيرات) المستقل. إذا كانت تباينات الملاحظات ليست كلها متماثلة ( تغايرية) ، فستكون هناك حاجة إلى متغير وزن ويتم حل مشكلة المربعات الصغرى الموزونة لتقليل المجموع المرجح لمربعات البقايا للعثور على أفضل المعلمات المناسبة.
ستسمح ميزتنا الجديدة للمستخدم بتحديد متغير الوزن كدالة للمعلمات الموجودة في النموذج المناسب. تمت إضافة سبع وظائف وزن محددة مسبقًا إلى كل وظيفة مناسبة (تختلف الوظائف ثلاثية الأبعاد قليلاً). السبعة الموضحة أدناه هي 1/y، 1/y 2 ، 1/x، 1/x 2 ، 1/متوقع، 1/متنبأ 2 وكوشي.
على سبيل المثال، يحتوي الملف المناسب لوظيفة الكثافة اللوغاريتمية الطبيعية على معادلة الكثافة اللوغاريتمية الطبيعية lognormden(x,a,b)، ومعادلات لتقدير المعلمة الأولية التلقائية ووظائف الترجيح السبع الجديدة.
[Variables]
س = العمود (1)
ص = العمود (2)
reciprocal_y = 1/abs(y)
reciprocal_ysquare = 1/y^2
reciprocal_x = 1/أبس(س)
reciprocal_xsquare = 1/x^2
reciprocal_pred = 1/أبس(و)
reciprocal_predsqr = 1/f^2
الوزن_كوشي = 1/(1+4*(yf)^2)
‘وظائف تقدير المعلمة الأولية التلقائية
فخ(ف,ص)=.5*المجموع(({0,q}+{q,0})[data(2,size(q))] *فرق (ص)[data(2,size(r))] )
الصورة = فرز (معقد (س، ص)، س)
u = كتلة فرعية(s,1,1,1, size(x))
v = كتلة فرعية(s,2,1,2, size(y))
أعني = فخ (u*v،u)
varest=فخ((u-الأسوء)^2*v,u)
ع = 1 + أفاريست / أتعس ^ 2
[Parameters]
أ= إذا (أعني> 0, قانون الجنسية (يعني/جذر(ع)), 0)
ب = إذا (ص> = 1، الجذر التربيعي (ln(p)))، 1)
[Equation]
f=lognormden(x,a,b)
تناسب f إلى y
”تناسب f إلى y مع الوزن المتبادل_y
”تناسب f إلى y مع الوزن reciprocal_ysquare
”تناسب f إلى y مع الوزن reciprocal_x
”تناسب f إلى y مع الوزن reciprocal_xsquare
”تناسب f إلى y مع الوزن المتبادل
”تناسب f إلى y مع الوزن reciprocal_predsqr
”تناسب f إلى y مع الوزن Weight_Cauchy
[Constraints]
ب> 0
[Options]
التسامح = 1e-010
حجم الخطوات = 1
التكرارات = 200
وظائف الوزن في الانحدار غير الخطي – تستخدم عناصر معادلة SigmaPlot أحيانًا متغير وزن بغرض تعيين وزن لكل ملاحظة (أو استجابة) في مجموعة بيانات الانحدار. يقيس وزن الملاحظة عدم اليقين بالنسبة للتوزيع الاحتمالي الذي تم أخذ العينات منه. يشير الوزن الأكبر إلى ملاحظة تختلف قليلًا عن المتوسط الحقيقي لتوزيعها بينما يشير الوزن الأصغر إلى ملاحظة تم أخذ عينات منها أكثر من ذيل توزيعها.
في ظل الافتراضات الإحصائية لتقدير معلمات النموذج المناسب باستخدام نهج المربعات الصغرى، تكون الأوزان، حتى عامل القياس، مساوية لمقلوب التباينات السكانية للتوزيعات (الغاوسية) التي تم أخذ عينات منها الملاحظات. هنا، نحدد المتبقي ، والذي يسمى أحيانًا الخام المتبقي ، على أنه الفرق بين الملاحظة والقيمة المتوقعة (قيمة النموذج المناسب) عند قيمة معينة للمتغير (المتغيرات) المستقل. إذا كانت تباينات الملاحظات ليست كلها متماثلة ( تغايرية) ، فستكون هناك حاجة إلى متغير وزن ويتم حل مشكلة المربعات الصغرى الموزونة لتقليل المجموع المرجح لمربعات البقايا للعثور على أفضل المعلمات المناسبة.
ستسمح ميزتنا الجديدة للمستخدم بتحديد متغير الوزن كدالة للمعلمات الموجودة في النموذج المناسب. تمت إضافة سبع وظائف وزن محددة مسبقًا إلى كل وظيفة مناسبة (تختلف الوظائف ثلاثية الأبعاد قليلاً). السبعة الموضحة أدناه هي 1/y، 1/y 2 ، 1/x، 1/x 2 ، 1/متوقع، 1/متنبأ 2 وكوشي.
 أحد تطبيقات هذا الترجيح التكيفي الأكثر عمومية هو في المواقف التي لا يمكن فيها تحديد تباينات الملاحظات قبل إجراء الملاءمة. على سبيل المثال، إذا كانت جميع الملاحظات موزعة بواسون، فإن متوسط عدد السكان، وهو ما تقدره القيم المتوقعة، يساوي تباينات المجتمع. على الرغم من أن أسلوب المربعات الصغرى لتقدير المعلمات مصمم للبيانات الموزعة بشكل طبيعي، إلا أنه يتم استخدام توزيعات أخرى أحيانًا مع المربعات الصغرى عندما لا تتوفر طرق أخرى. في حالة بيانات بواسون ، نحتاج إلى تعريف متغير الوزن باعتباره مقلوب القيم المتوقعة. يُشار إلى هذا الإجراء أحيانًا باسم “الترجيح بالقيم المتوقعة”.
تطبيق آخر للترجيح التكيفي هو الحصول على إجراءات قوية لتقدير المعلمات التي تخفف من آثار القيم المتطرفة. في بعض الأحيان، قد يكون هناك عدد قليل من الملاحظات في مجموعة البيانات التي يتم أخذ عينات منها من ذيل توزيعاتها باحتمالية صغيرة، أو هناك عدد قليل من الملاحظات التي يتم أخذ عينات منها من توزيعات تنحرف قليلاً عن افتراض الحالة الطبيعية المستخدم في تقدير المربعات الصغرى وبالتالي تلوث مجموعة البيانات. هذه الملاحظات الشاذة، والتي تسمى القيم المتطرفة في متغير الاستجابة ، يمكن أن يكون لها تأثير كبير على نتائج الملاءمة لأنها تحتوي على بقايا كبيرة نسبيًا (خام أو مرجح) وبالتالي تضخم مجموع المربعات التي يتم تقليلها.
تتمثل إحدى طرق التخفيف من آثار القيم المتطرفة في استخدام متغير الوزن الذي يمثل دالة للقيم المتبقية (وبالتالي، أيضًا وظيفة للمعلمات)، حيث يرتبط الوزن المخصص للملاحظة عكسيًا بحجم المتبقي. يعتمد تعريف وظيفة الترجيح المستخدمة على افتراضات حول توزيعات الملاحظات (بافتراض أنها ليست طبيعية) ومخطط لتحديد حجم المتبقي الذي يجب تحمله. يتم تعريف دالة الترجيح كوشي من حيث القيم المتبقية، yf حيث y هي قيمة المتغير التابع وf هي الدالة الملائمة، ويمكن استخدامها لتقليل تأثير القيم المتطرفة.
الوزن_كوشي = 1/(1+4*(yf)^2)
تعتمد خوارزمية تقدير المعلمة التي نستخدمها للترجيح التكيفي، والمربعات الصغرى المعاد وزنها بشكل متكرر (IRLS)، على حل سلسلة من مشاكل المربعات الصغرى ذات الوزن الثابت حيث يتم حل كل مشكلة فرعية باستخدام تطبيقنا الحالي لخوارزمية Levenberg-Marquardt . تبدأ هذه العملية بتقييم الأوزان باستخدام قيم المعلمات الأولية ثم تقليل مجموع المربعات بهذه الأوزان الثابتة. يتم بعد ذلك استخدام المعلمات الأكثر ملائمة لإعادة تقييم الأوزان.
باستخدام قيم الوزن الجديدة، يتم تكرار العملية المذكورة أعلاه لتقليل مجموع المربعات. ونستمر على هذا المنوال حتى يتحقق التقارب. المعيار المستخدم للتقارب هو أن يكون الخطأ النسبي بين الجذر التربيعي لمجموع البقايا المرجحة لقيم المعلمات الحالية والجذر التربيعي لمجموع البقايا المرجحة لقيم معلمات التكرار السابق أقل من قيمة التسامح المنصوص عليها في عنصر المعادلة. وكما هو الحال مع إجراءات التقدير الأخرى، فإن التقارب غير مضمون.
أحد تطبيقات هذا الترجيح التكيفي الأكثر عمومية هو في المواقف التي لا يمكن فيها تحديد تباينات الملاحظات قبل إجراء الملاءمة. على سبيل المثال، إذا كانت جميع الملاحظات موزعة بواسون، فإن متوسط عدد السكان، وهو ما تقدره القيم المتوقعة، يساوي تباينات المجتمع. على الرغم من أن أسلوب المربعات الصغرى لتقدير المعلمات مصمم للبيانات الموزعة بشكل طبيعي، إلا أنه يتم استخدام توزيعات أخرى أحيانًا مع المربعات الصغرى عندما لا تتوفر طرق أخرى. في حالة بيانات بواسون ، نحتاج إلى تعريف متغير الوزن باعتباره مقلوب القيم المتوقعة. يُشار إلى هذا الإجراء أحيانًا باسم “الترجيح بالقيم المتوقعة”.
تطبيق آخر للترجيح التكيفي هو الحصول على إجراءات قوية لتقدير المعلمات التي تخفف من آثار القيم المتطرفة. في بعض الأحيان، قد يكون هناك عدد قليل من الملاحظات في مجموعة البيانات التي يتم أخذ عينات منها من ذيل توزيعاتها باحتمالية صغيرة، أو هناك عدد قليل من الملاحظات التي يتم أخذ عينات منها من توزيعات تنحرف قليلاً عن افتراض الحالة الطبيعية المستخدم في تقدير المربعات الصغرى وبالتالي تلوث مجموعة البيانات. هذه الملاحظات الشاذة، والتي تسمى القيم المتطرفة في متغير الاستجابة ، يمكن أن يكون لها تأثير كبير على نتائج الملاءمة لأنها تحتوي على بقايا كبيرة نسبيًا (خام أو مرجح) وبالتالي تضخم مجموع المربعات التي يتم تقليلها.
تتمثل إحدى طرق التخفيف من آثار القيم المتطرفة في استخدام متغير الوزن الذي يمثل دالة للقيم المتبقية (وبالتالي، أيضًا وظيفة للمعلمات)، حيث يرتبط الوزن المخصص للملاحظة عكسيًا بحجم المتبقي. يعتمد تعريف وظيفة الترجيح المستخدمة على افتراضات حول توزيعات الملاحظات (بافتراض أنها ليست طبيعية) ومخطط لتحديد حجم المتبقي الذي يجب تحمله. يتم تعريف دالة الترجيح كوشي من حيث القيم المتبقية، yf حيث y هي قيمة المتغير التابع وf هي الدالة الملائمة، ويمكن استخدامها لتقليل تأثير القيم المتطرفة.
الوزن_كوشي = 1/(1+4*(yf)^2)
تعتمد خوارزمية تقدير المعلمة التي نستخدمها للترجيح التكيفي، والمربعات الصغرى المعاد وزنها بشكل متكرر (IRLS)، على حل سلسلة من مشاكل المربعات الصغرى ذات الوزن الثابت حيث يتم حل كل مشكلة فرعية باستخدام تطبيقنا الحالي لخوارزمية Levenberg-Marquardt . تبدأ هذه العملية بتقييم الأوزان باستخدام قيم المعلمات الأولية ثم تقليل مجموع المربعات بهذه الأوزان الثابتة. يتم بعد ذلك استخدام المعلمات الأكثر ملائمة لإعادة تقييم الأوزان.
باستخدام قيم الوزن الجديدة، يتم تكرار العملية المذكورة أعلاه لتقليل مجموع المربعات. ونستمر على هذا المنوال حتى يتحقق التقارب. المعيار المستخدم للتقارب هو أن يكون الخطأ النسبي بين الجذر التربيعي لمجموع البقايا المرجحة لقيم المعلمات الحالية والجذر التربيعي لمجموع البقايا المرجحة لقيم معلمات التكرار السابق أقل من قيمة التسامح المنصوص عليها في عنصر المعادلة. وكما هو الحال مع إجراءات التقدير الأخرى، فإن التقارب غير مضمون.