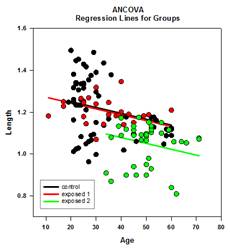
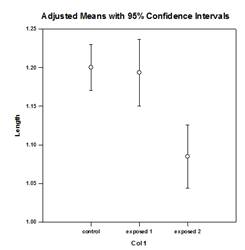
多重比較の改善 – 重複比較のP値計算が大幅に改善されました。 以下の多重比較手続き、Tukey(ノンパラメトリック検定)、SNK(ノンパラメトリック検定)、Dunnettの、Dunnの(ノンパラメトリックのみ)、Duncanは、分析的にp値を計算するのではなく、計算された検定統計量が群平均の有意差を表しているかどうかを、必要に応じて補間を用いて決定するために、特定の分布の臨界値のルックアップテーブルを使用した。 したがって、これらの検定ではp値は報告されず、有意差が存在するかどうかの結論のみが報告された。 この方法の大きな問題は、ルックアップテーブルが0.05と0.01の2つの有意水準でしか利用できないことである。 もう一つの問題は、多くの顧客がp値を知りたがることだ。 SigmaPlotでは、すべてのポストホック手続きの検定統計量の分布を計算するアルゴリズムがコード化され、ルックアップテーブルは廃止されました。 その結果、すべてのpost-hoc手続きの調整されたp値がレポートに掲載されるようになった。 また、多重比較の有意水準を.05や.01に制限する必要もなくなった。 その代わりに、多重比較の有意水準は、メイン(オムニバス)検定の有意水準と同じになる。 このp値に制限はなく、どのような有効な値を用いてもよい。
赤池情報量規準 (AICc) – 赤池情報量規準が回帰ウィザードと動的フィットウィザードのレポートとレポートオプションダイアログに追加されました。 これは、与えられたデータ集合に回帰モデルをフィッティングする際の相対的なパフォーマンスを測定する方法を提供する。 情報エントロピーの概念に基づくこの基準は、データを記述するためにモデルを使用する際に失われる情報の相対的な尺度を提供する。
より具体的には、推定モデルの尤度を最大化すること(データが正規分布している場合、残差平方和を最小化することと同じ)と、モデルの自由パラメータの数を最小に保ち、複雑さを軽減することのトレードオフを与える。 適合度はパラメータを増やすことでほとんどの場合改善されるが、過剰適合は入力データの変化に対するモデルの感度を上げ、予測能力を台無しにする。
AICを使用する基本的な理由は、モデル選択の指針としてである。 実際には、候補モデルの集合と与えられたデータセットに対して計算される。 AIC値が最小のモデルが、集合の中で「真の」モデルを最もよく表すモデル、つまりAICが推定するために設計された情報損失を最小化するモデルとして選択される。
最小のAICを持つモデルが決定された後、最小のAICを持つモデルに対して情報損失を減らす確率を測定するために、他の候補モデルの各々について相対尤度を計算することもできる。 相対尤度は、調査者がセット内の複数のモデルをさらに検討するために保持すべきかどうかを決定する際に役立ちます。
AICの計算は、Akaike1によって得られた以下の一般式に基づいている。
![]()
ここで、![]() はモデルの自由パラメーターの数であり、
はモデルの自由パラメーターの数であり、![]() は推定モデルの尤度関数の最大化値である。
は推定モデルの尤度関数の最大化値である。
データ![]() のサンプルサイズが、パラメータ
のサンプルサイズが、パラメータ![]() の数に対して小さい場合(著者によっては、
の数に対して小さい場合(著者によっては、![]() が
が![]() の数倍以下である場合)、AICはオーバーフィッティングから保護するために、それほどうまく機能しません。 この場合、AICの補正版が次のように与えられる:
の数倍以下である場合)、AICはオーバーフィッティングから保護するために、それほどうまく機能しません。 この場合、AICの補正版が次のように与えられる:
![]()
余分なパラメータがある場合、AICcはAICよりも大きなペナルティを課すことがわかる。 ほとんどの著者は、すべての状況においてAICの代わりにAICcを使うべきだという意見で一致しているようだ。
確率フィット関数– 24の新しい確率フィット関数がフィットライブラリstandard.jflに追加されました。 これらの関数と方程式、グラフの形を以下に示す:

例として、対数正規密度関数のフィットファイルには、対数正規密度lognormden(x,a,b)の式、自動初期パラメータ推定の式、7つの新しい重み付け関数が含まれています。
[Variables]
x = col(1)
y = col(2)
逆y = 1/abs(y)
逆二乗 = 1/y^2
逆数x = 1/abs(x)
逆2乗 = 1/x^2
reciprocal_pred = 1/abs(f)
レシプロ・プレッド・スクエア = 1/f^2
Weight_Cauchy = 1/(1+4*(y-f)^2)
自動初期パラメータ推定関数
trap(q,r)=.5*total(({0,q}+{q,0})[data(2,size(q))]*diff(r)[data(2,size(r))])
s=sort(complex(x,y),x)
u = サブブロック(s,1,1,1, size(x))
v = サブブロック(s,2,1,2, size(y))
meanest = trap(u*v,u)
varest=trap((u-meanest)^2*v,u)
p = 1+varest/meanest^2
[Parameters]
a= if(meanest> 0, ln(meanest/sqrt(p)), 0)
b= if(p>= 1, sqrt(ln(p)), 1)
[Equation]
f=lognormden(x,a,b)
yに合う
「yにfを重みreciprocal_yで当てはめる
「yにfを重み付きで当てはめる。
「yにfを重みの逆数xで当てはめる
「yにfを重み付きで当てはめる。
「fをyにフィットさせる。
「fをyにフィットさせる。
「重みweight_Cauchyでyにfを合わせる
[Constraints]
b>0
[Options]
公差=1e-010
stepize=1
反復=200
非線形回帰における重み関数– SigmaPlot 方程式の項目は、回帰データ集合の各オブザベーション(または応答)に重みを割り当てる目的で、重み変数を使うことがあります。 オブザベーションの重みは、それがサンプリングされた確率分布に対する不確実性を測定します。 より大きなウェイトは、その分布の真の平均からほとんど変化しないオブザベーションを示し、より小さなウェイトは、その分布のテールからより多くサンプリングされたオブザベーションを指す。
最小2乗アプローチを用いて適合モデルのパラメータを推定するための統計的仮定の下では,重みは,スケール・ファクターまで,オブザベーションがサンプリングされた(ガウス)分布の母分散の逆数に等しい. ここで、残差(生の残差と呼ばれることもある)を、独立変数の任意の値でのオブザベーションと予測値(適合モデルの値)の差と定義する。 オブザベーションの分散がすべて同じでない場合(異分散性)、重み変数が必要となり、残差の重み付き2乗和を最小化する重み付き最小2乗問題が、ベスト・フィット・パラメータを見つけるために解かれる。
新機能では、フィットモデルに含まれるパラメータの関数として重み変数を定義することができます。 各フィット関数には、あらかじめ定義された7つの重み関数が追加されている(3D関数は若干異なる)。 以下の7つは、1/y、1/y2、1/x、1/x2、1/predicted、1/predicteds2、Cauchyである。

このより一般的な適応重みづけの1つの応用は、適合を実行する前にオブザベーションの分散が決定できない状況である。 たとえば、すべてのオブザベーションがポアソン分布であれば、予測値が推定している母平均は母分散に等しい。 パラメータを推定するための最小二乗法は正規分布データ用に設計されているが、他の方法が利用できない場合、最小二乗法で他の分布が使われることもある。 ポアソン・データの場合、重み変数を予測値の逆数として定義する必要がある。 この手順は「予測値による重み付け」と呼ばれることもある。
適応的重み付けのもう一つの応用は、外れ値の影響を軽減するロバストなパラメータ推定手順を得ることである。 時折、小さな確率でそれらの分布の末尾からサンプリングされたデータ集合のオブザベーションがいくつかあったり、最小2乗推定で使用される正規性の仮定からわずかに逸脱した分布からサンプリングされたオブザベーションがいくつかあったりして、データ集合を汚染することがある。 応答変数の外れ値と呼ばれるこれらの異常なオブザベーションは、比較的大きな(生のまたは重みづけされた)残差を持ち、したがって最小化される平方和を増大させるので、適合結果に大きな影響を持つことがある。
外れ値の効果を緩和する1つの方法は、残差の関数(したがって、パラメータの関数でもある)である重み変数を使用することであり、ここでオブザベーションに割り当てられる重みは、残差のサイズに反比例する。 どのような重みづけ関数を使用するかの定義は、オブザベーションの分布に関する仮定(それらが正規分布でないと仮定する)、およびどの程度の残差を許容するかを決定するスキームに依存する。 コーシー重み付け関数は、残差y-f(yは従属変数値、fはフィッティング関数)で定義され、外れ値の影響を最小化するために使用できます。
Weight_Cauchy = 1/(1+4*(y-f)^2)
適応的重み付けに使用するパラメータ推定アルゴリズムである反復再重み付け最小二乗法(IRLS)は、定重み付け最小二乗法問題のシーケンスを解くことに基づいており、各サブ問題は現在実装しているレーベンバーグ・マルカールト・アルゴリズムを使用して解かれる。 このプロセスは、パラメータの初期値を用いて重みを評価し、その固定重みで平方和を最小化することから始まる。 そして、ベストフィットのパラメーターを用いて重みを再評価する。
新しいウエイト値で、上記の二乗和を最小化するプロセスを繰り返す。 収束するまでこの作業を続ける。 収束の基準は、現在のパラメータ値に対する重み付き残差の総和の平方根と、前の反復のパラメータ値に対する重み付き残差の総和の平方根との間の相対誤差が、式項目で設定された許容値より小さいことである。 他の推定方法と同様、収束は保証されない。