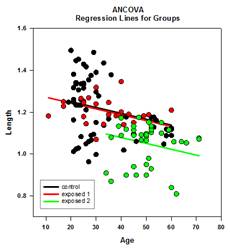
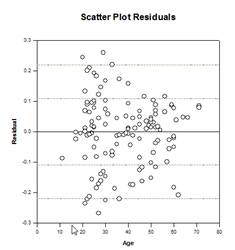
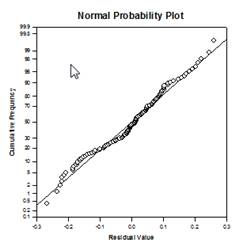
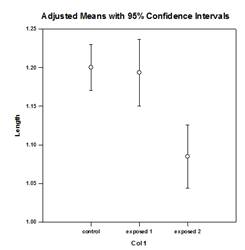
다중 비교 개선 – 다중 비교 P값 계산이 크게 개선되었습니다. 다음과 같은 다중 비교 절차, Tukey(비모수 검정), SNK(비모수 검정), Dunnett’s, Dunn’s(비모수 검정만 해당), Duncan은 p값을 분석적으로 계산하지 않고 대신 특정 분포에 대한 임계값 조회표를 사용하여 계산된 검정 통계가 그룹 평균에서 유의미한 차이를 나타내는지 여부를 필요한 경우 보간법을 사용하여 결정합니다. 따라서 이러한 테스트에 대한 p값은 보고되지 않고 유의미한 차이가 존재하는지 여부에 대한 결론만 보고되었습니다. 이 접근 방식의 가장 큰 문제점은 조회 테이블이 0.05와 0.01의 두 가지 유의 수준에서만 사용 가능하다는 점입니다. 또 다른 문제는 많은 고객이 p값을 알고 싶어한다는 것입니다. 시그마플롯의 경우, 모든 사후 절차에 대한 테스트 통계의 분포를 계산하도록 알고리즘이 코딩되어 조회 테이블이 더 이상 필요하지 않게 되었습니다. 그 결과, 이제 모든 사후 절차에 대한 조정된 p-값이 보고서에 배치됩니다. 또한 더 이상 다중 비교의 유의 수준을 0.05 또는 0.01로 제한할 필요가 없습니다. 대신 다중 비교의 유의 수준은 주(옴니버스) 테스트의 유의 수준과 동일합니다. 이 p 값에는 제한이 없으며 유효한 모든 값을 사용할 수 있습니다.
카이제 정보 기준(AICc ) – 회귀 마법사 및 동적 맞춤 마법사 보고서와 보고서 옵션 대화 상자에 카이제 정보 기준이 추가되었습니다. 주어진 데이터 세트에 회귀 모델을 맞출 때 상대적인 성능을 측정하는 방법을 제공합니다. 정보 엔트로피의 개념에 기반한 이 기준은 데이터를 설명하기 위해 모델을 사용할 때 손실되는 정보의 상대적인 척도를 제공합니다.
더 구체적으로 말하면, 추정 모델의 가능성을 최대화하는 것(데이터가 정규 분포인 경우 잔차 제곱의 합을 최소화하는 것과 동일)과 모델의 자유 변수 수를 최소로 유지하여 복잡성을 줄이는 것 사이에서 절충점을 찾습니다. 적합도는 매개변수를 추가하면 거의 항상 향상되지만, 과적합은 입력 데이터의 변화에 대한 모델의 민감도를 증가시켜 예측 기능을 망칠 수 있습니다.
AIC를 사용하는 기본적인 이유는 모델 선택을 위한 가이드입니다. 실제로는 후보 모델 세트와 주어진 데이터 세트에 대해 계산됩니다. AIC 값이 가장 작은 모델이 집합에서 “진정한” 모델을 가장 잘 나타내는 모델, 즉 AIC가 추정하도록 설계된 정보 손실을 최소화하는 모델로 선택됩니다.
AIC가 최소인 모델을 결정한 후에는 다른 후보 모델 각각에 대해 상대적 가능성을 계산하여 AIC가 최소인 모델에 비해 정보 손실을 줄일 수 있는 확률을 측정할 수도 있습니다. 상대적 가능성은 조사자가 추가 검토를 위해 세트에 있는 두 개 이상의 모델을 유지해야 하는지 여부를 결정하는 데 도움이 될 수 있습니다.
AIC 계산은 다음과 같은 일반적인 공식을 기반으로 합니다.
![]()
여기서 ![]() 은 모델의 자유 변수 수이고
은 모델의 자유 변수 수이고 ![]() 은 추정 모델의 확률 함수의 최대값입니다.
은 추정 모델의 확률 함수의 최대값입니다.
데이터의 표본 크기 ![]() 가 매개변수 수
가 매개변수 수![]() 에 비해 작을 경우(일부 저자는
에 비해 작을 경우(일부 저자는 ![]() 가
가 ![]() 보다 몇 배 이상 크지 않을 때라고 말합니다.) 과적합을 방지하기 위해 AIC 가 잘 작동하지 않습니다. 이 경우 수정된 버전의 AIC가 제공됩니다:
보다 몇 배 이상 크지 않을 때라고 말합니다.) 과적합을 방지하기 위해 AIC 가 잘 작동하지 않습니다. 이 경우 수정된 버전의 AIC가 제공됩니다:
![]()
추가 매개변수가 있는 경우 AICc가 AIC보다 더 큰 페널티를 부과하는 것을 알 수 있습니다. 대부분의 작성자는 모든 상황에서 AIC 대신 AICc를 사용해야 한다는 데 동의하는 것 같습니다.
확률 맞춤 함수 – 24개의 새로운 확률 맞춤 함수가 맞춤 라이브러리 standard.jfl에 추가되었습니다. 이러한 함수와 일부 방정식 및 그래프 모양은 아래에 나와 있습니다:

예를 들어 로그 정규 밀도 함수에 대한 적합 파일에는 로그 정규 밀도 lognormden(x,a,b) 방정식, 자동 초기 파라미터 추정 방정식, 7개의 새로운 가중치 함수가 포함되어 있습니다.
[Variables]
x = col(1)
y = col(2)
RECIPROCAL_Y = 1/abs(Y)
RECIPROCAL_YSQUARE = 1/Y^2
RECIPROCAL_X = 1/abs(X)
RECIPROCAL_XSQUARE = 1/X^2
RECIPROCAL_Pred = 1/abs(f)
RECIPROCAL_PredSQR = 1/f^2
weight_Cauchy = 1/(1+4*(y-f)^2)
‘자동 초기 매개변수 추정 함수’
trap(q,r)=.5*total(({0,q}+{q,0})[data(2,size(q))]*diff(r)[data(2,size(r))])
s=sort(complex(x,y),x)
u = subblock(s,1,1,1, size(x))
v = subblock(s,2,1,2, size(y))
평균값 = 트랩(U*V,U)
varest=트랩((u-평균)^2*v,u)
p = 1+베스트/평균^2
[Parameters]
a= if(meanest > 0, ln(meanest/sqrt(p)), 0)
b= if(p >= 1, sqrt(ln(p)), 1)
[Equation]
F=로그노름덴(X,A,B)
FIT F TO Y
“FIT F TO Y WITH WEIGHT RECIPROCAL_Y
“FIT F TO Y WITH WEIGHT RECIPROCAL_YSQUARE
“FIT F TO Y WITH WEIGHT RECIPROCAL_X
“FIT F TO Y WITH WEIGHT RECIPROCAL_XSQUARE
“FIT F TO Y WITH WEIGHT RECIPROCAL_PED
“FIT F TO Y WITH WEIGHT RECIPROCAL_PREDSQR
“fit f to y with weight weight_Cauchy
[Constraints]
b>0
[Options]
허용오차=1e-010
stepsize=1
iterations=200
비선형 회귀의 가중치 함수 – 시그마플롯 방정식 항목은 회귀 데이터 집합의 각 관측값(또는 응답)에 가중치를 할당하기 위해 가중치 변수를 사용하는 경우가 있습니다. 관측값의 가중치는 관측값이 샘플링된 확률 분포와 관련된 불확실성을 측정합니다. 가중치가 클수록 분포의 실제 평균과 거의 차이가 나지 않는 관측값을 나타내고, 가중치가 작을수록 분포의 꼬리에서 더 많이 샘플링된 관측값을 나타냅니다.
최소제곱 접근법을 사용하여 적합 모델의 매개변수를 추정하는 통계적 가정 하에서 가중치는 관측값이 샘플링된 (가우스) 분포의 모집단 분산의 역수와 같은 척도 계수까지입니다. 여기서 잔차( 원시 잔차라고도 함)는 주어진 독립 변수의 값에 대한 관측값과 예측값(적합 모델의 값)의 차이로 정의합니다. 관측값의 분산이 모두 같지 않은 경우(이질적 공분산) 가중치 변수가 필요하며, 가중치 최소제곱 문제 (잔차의 가중치 제곱 합을 최소화하는 문제 )를 해결하여 가장 잘 맞는 매개 변수를 찾아야 합니다.
새로운 기능을 통해 사용자는 맞춤 모델에 포함된 파라미터의 함수로 가중치 변수를 정의할 수 있습니다. 각 맞춤 기능에 7개의 사전 정의된 체중 함수가 추가되었습니다(3D 기능은 약간 다릅니다). 아래에 표시된 7개는 1/y, 1/y2, 1/x, 1/x2, 1/예측된, 1/예측된2 및 코시입니다.

이 보다 일반적인 적응형 가중치의 한 가지 적용 사례는 맞춤을 수행하기 전에 관측값의 분산을 결정할 수 없는 상황입니다. 예를 들어 모든 관측값이 푸아송 분포인 경우, 예측값이 추정하는 모집단 평균은 모집단 분산과 동일합니다. 매개변수 추정을 위한 최소제곱 접근법은 정규 분포 데이터에 맞게 설계되었지만, 다른 방법을 사용할 수 없는 경우 다른 분포를 최소제곱과 함께 사용하는 경우도 있습니다. 푸아송 데이터의 경우, 가중치 변수를 예측 값의 역수로 정의해야 합니다. 이 절차를 “예측 값에 의한 가중치 부여”라고도 합니다.
적응형 가중치의 또 다른 응용 분야는 이상값의 영향을 완화하는 매개변수 추정을 위한 강력한 절차를 얻는 것입니다. 때때로 데이터 집합에 작은 확률로 분포의 꼬리에서 샘플링된 몇 개의 관측값이 있거나 최소자승추정에 사용된 정규성 가정에서 약간 벗어난 분포에서 샘플링된 몇 개의 관측값이 있어 데이터 집합이 오염될 수 있습니다. 응답 변수의 이상값이라고 하는 이러한 비정상적인 관측값은 상대적으로 큰(원시 또는 가중치) 잔차를 가지므로 최소화되는 제곱의 합을 부풀리기 때문에 적합 결과에 상당한 영향을 미칠 수 있습니다.
이상값의 영향을 완화하는 한 가지 방법은 잔차의 함수(따라서 매개변수의 함수이기도 함)인 가중치 변수를 사용하는 것인데, 여기서 관측값에 할당된 가중치는 잔차의 크기와 반비례 관계에 있습니다. 사용할 가중치 함수의 정의는 관측값의 분포에 대한 가정(정규 분포가 아니라고 가정)과 허용할 잔차의 크기를 결정하는 방식에 따라 달라집니다. 코시 가중치 함수는 잔차, 즉 y-f로 정의되며, 여기서 y는 종속 변수 값이고 f는 피팅 함수이며, 이상값의 영향을 최소화하는 데 사용할 수 있습니다.
weight_Cauchy = 1/(1+4*(y-f)^2)
적응형 가중치 적용에 사용하는 매개변수 추정 알고리즘인 반복적 가중치 최소제곱(IRLS)은 현재 구현된 레벤버그-마쿼트 알고리즘을 사용하여 각 하위 문제를 푸는 일련의 상수 가중치 최소제곱 문제를 해결하는 것을 기반으로 합니다. 이 프로세스는 초기 파라미터 값을 사용하여 가중치를 평가한 다음 이러한 고정 가중치로 제곱의 합을 최소화하는 것으로 시작됩니다. 그런 다음 가장 적합한 매개변수를 사용하여 가중치를 다시 평가합니다.
새로운 가중치 값을 사용하면 위의 제곱의 합을 최소화하는 과정이 반복됩니다. 융합이 이루어질 때까지 이러한 방식을 계속 유지합니다. 수렴에 사용되는 기준은 현재 파라미터 값에 대한 가중 잔차 합의 제곱근과 이전 반복의 파라미터 값에 대한 가중 잔차 합의 제곱근 사이의 상대 오차가 방정식 항목에 설정된 허용 오차 값보다 작은지 여부입니다. 다른 추정 절차와 마찬가지로 수렴이 보장되는 것은 아닙니다.