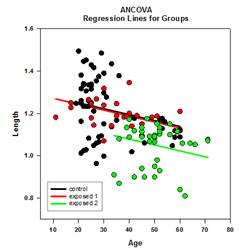
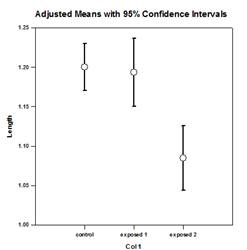
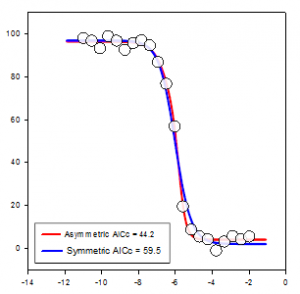
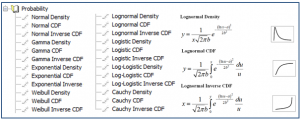
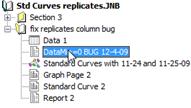
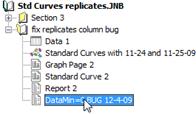
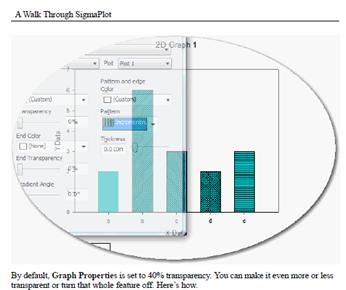
- Waldgrundstücke
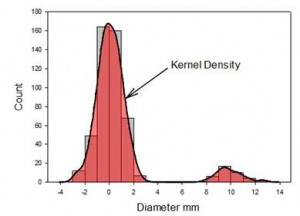
- Kerndichtediagramme
- 10 neue Farbschemata
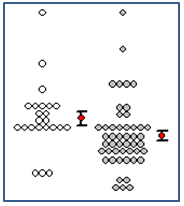
- Punktdichtediagramm mit Mittelwert und Standardfehlerbalken
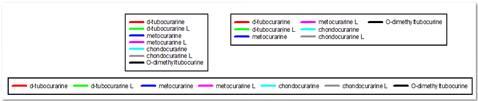
- Legende Verbesserungen
- Horizontale, vertikale und rechteckige Legendenformen
- Cursor über Seite oder oberen oder unteren Griff

-
- ermöglicht mehrspaltige Legenden
-
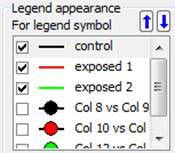
- Benutzeroberfläche zum Einstellen der Anzahl der Spalten für Legendenelemente im Dialogfeld Eigenschaften. Die zulässigen Spaltennummern werden in der Kombinationsliste angezeigt
- Ändern Sie die Anzahl der Spalten für die Legende, indem Sie den mittleren Griff im Begrenzungsrahmen auswählen und ziehen.
- Legendenelemente neu ordnen
- Über den Eigenschaftsdialog – Verschieben Sie ein oder mehrere Legendenelemente nach oben oder unten, indem Sie die Aufwärts-/Abwärts-Steuerung oben im Listenfeld verwenden.
- Durch Bewegen des Cursors – ein oder mehrere Legendenelemente nach oben oder unten verschieben. Wählen Sie das/die Legendenelement(e) und verwenden Sie die Pfeiltasten der Tastatur, um sich innerhalb des Begrenzungsrahmens zu bewegen.
- Durch Mausauswahl und Cursorbewegung für Elemente im Begrenzungsrahmen
- Eigenschaftseinstellungen für einzelne Legendenelemente – wählen Sie einzelne Legendenelemente aus und verwenden Sie die Mini-Symbolleiste, um die Eigenschaften zu ändern
- Legende Box leeren Bereich Kontrolle durch Cursor
- Cursor über Eckgriff

- ermöglicht eine proportionale Größenänderung
- Einfache Direktbeschriftung hinzufügen
- Unterstützung von „Direct Labeling“ im Eigenschaftsdialog über das Kontrollkästchen „Direct Labeling“.
- Gruppierung der Legendenelemente aufheben – die einzelnen Legendenelemente können an die gewünschte Stelle verschoben werden und sich zusammen mit dem Diagramm bewegen
- Die Unterstützung für Legendentitel wurde hinzugefügt (standardmäßig kein Titel). Der Benutzer kann dem Legendenfeld einen Titel hinzufügen, indem er das Legenden-Eigenschaftsfeld verwendet
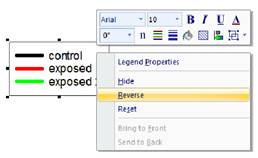
- Umkehrung der Legendenelemente über das Rechtsklick-Kontextmenü
- Öffnen Sie die Legendeneigenschaften, indem Sie entweder auf Legende Vollton oder Legende Text doppelklicken.
- Zurücksetzen wurde zu Legenden hinzugefügt, um die Legendenoptionen auf die Standardwerte zurückzusetzen.
- Horizontale, vertikale und rechteckige Legendenformen