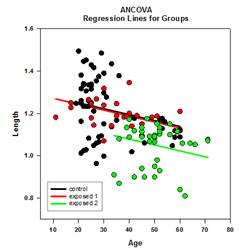
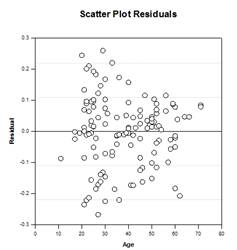
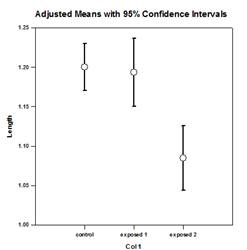
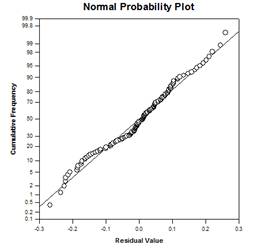
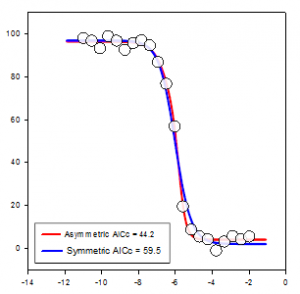
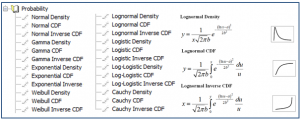
- 숲 플롯
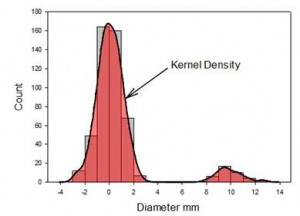
- 커널 밀도 플롯
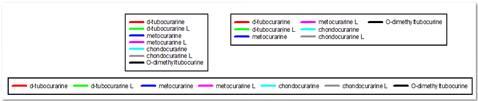
- 10가지 새로운 색상 구성표
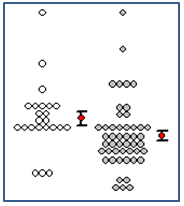
- 평균 및 표준 오차 막대가 있는 도트 밀도 그래프
- 범례 개선 사항
- 가로, 세로 및 직사각형 범례 모양
- 커서를 측면 또는 위쪽 또는 아래쪽 핸들에 놓습니다.

-
- 다중 열 범례 허용
-
- 속성 대화 상자에서 범례 항목 열의 개수를 설정하는 사용자 인터페이스입니다. 허용되는 열 번호는 콤보 목록에 표시됩니다.
- 경계 상자에서 가운데 핸들을 선택하고 끌어서 범례 항목 열의 수를 변경합니다.
- 범례 항목 재정렬
- 속성 대화 상자를 통해 – 목록 상자 상단의 위/아래 컨트롤을 사용하여 하나 또는 여러 범례 항목을 위/아래로 이동합니다.
- 커서 이동을 통해 – 하나 또는 여러 범례 항목을 위아래로 이동합니다. 범례 항목을 선택하고 키보드 위쪽 및 아래쪽 화살표 키를 사용하여 경계 상자 내에서 이동합니다.
- 경계 상자의 항목에 대한 마우스 선택 및 커서 이동을 통해
- 개별 범례 항목 속성 설정 – 개별 범례 항목을 선택하고 미니 도구 모음을 사용하여 속성을 변경합니다.
- 커서를 통한 범례 상자 빈 영역 제어
- 모서리 핸들 위로 커서 이동

- 비례 크기 조정 가능
- 간단한 직접 라벨링 추가
- 속성 대화 상자에서 “직접 레이블 지정” 확인란 컨트롤을 사용하여 “직접 레이블 지정” 지원
- 범례 항목 그룹 해제 – 개별 범례 항목을 원하는 위치로 이동하고 그래프와 함께 이동할 수 있습니다.
- 범례 제목 지원이 추가되었습니다(기본적으로 제목 없음). 사용자는 범례 속성 패널을 사용하여 범례 상자에 제목을 추가할 수 있습니다.
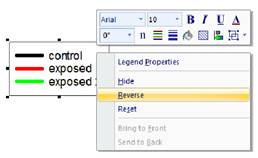
- 오른쪽 클릭 컨텍스트 메뉴를 사용하여 범례 항목 반전하기
- 범례 단색 또는 범례 텍스트를 두 번 클릭하여 범례 속성을 엽니다.
- 범례에 재설정이 추가되어 범례 옵션을 기본값으로 초기화할 수 있습니다.
- 가로, 세로 및 직사각형 범례 모양