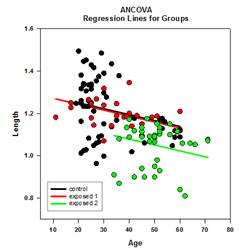
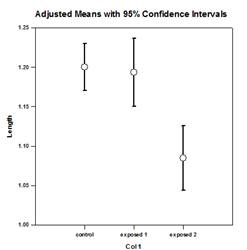
- Forest Plots
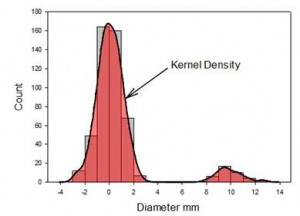
- Kernel Density Plots
- 10 New Color Schemes
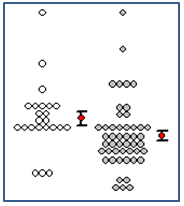
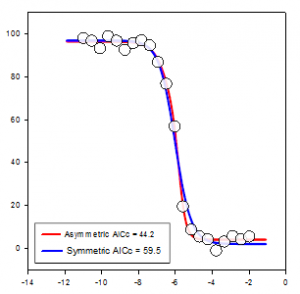
- Dot Density Graph with mean and standard error bars
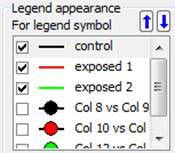
- Legend Improvements
- Horizontal, Vertical and Rectangular Legend Shapes
- Cursor over side or upper or lower handle

-
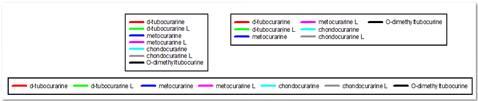
- allows for multi-column legends
-
- User interface to set number of legend item columns in the Properties dialog. The permissible column numbers are displayed in the combo list
- Change the number of legend item columns by selecting and dragging the middle handle in the bounding box
- Reorder legend items
- Through properties dialog – move one or multiple legend items up or down using the up/down control on top of the list box
- Through cursor movement – move one or multiple legend items up or down. Select the legend item(s) and use keyboard up and down arrow key for movement within the bounding box
- Through mouse select and cursor movement for items in the bounding box
- Individual legend items property settings – select individual legend items and use the mini tool bar to change the properties
- Legend box blank region control through cursor
- Cursor over corner handle

- allows proportional resizing
- Add simple direct labeling
- Support “Direct Labeling” in properties dialog using the checkbox control “Direct Labeling”
- Ungroup legend items – the individual legend items can be moved to preferred locations and move in conjunction with the graph
- Legend Title support has been added (no title by default). The user can add a title to the legend box using the legend properties panel
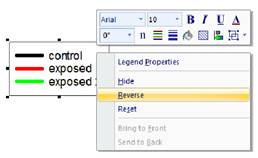
- Reverse the legend items using the right click context menu
- Open Legend Properties by double clicking either Legend Solid or Legend Text
- Reset has been added to legends to reset legend options to default
- Horizontal, Vertical and Rectangular Legend Shapes