- 林地
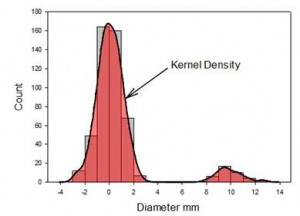
- 核密度图
- 10 种新配色方案
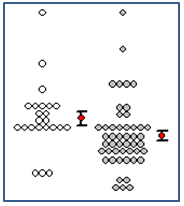
- 带平均值和标准误差条的点密度图
- 图例改进
- 水平、垂直和矩形图例形状
- 光标越过侧面或上下把手

-
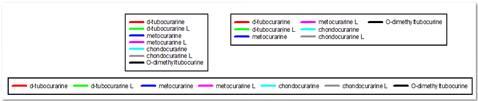
- 允许多栏图例
-
- 在属性对话框中设置图例项列数的用户界面。 允许的列编号显示在组合列表中
- 选择并拖动边界框中的中间手柄,更改图例项列数
- 重新排列图例项目
- 通过属性对话框–使用列表框顶部的上/下控件上下移动一个或多个图例项
- 通过光标移动 – 向上或向下移动一个或多个图例项。 选择图例项,使用键盘上下箭头键在边界框内移动
- 通过鼠标选择和光标移动,查看边界框中的项目
- 单个图例项属性设置–选择单个图例项并使用迷你工具栏更改属性
- 通过光标控制图例框空白区域
- 光标越过角把手

- 可按比例调整大小
- 添加简单的直接标签
- 使用复选框控件 “直接标记”,在属性对话框中支持 “直接标记
- 取消图例项分组–可将单个图例项移动到首选位置,并与图形一起移动
- 已添加图例标题支持(默认情况下无标题)。 用户可以使用图例属性面板为图例框添加标题
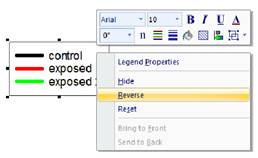
- 使用右键上下文菜单反转图例项
- 双击 “实体图例 “或 “文本图例”,打开 “图例属性”。
- 图例中添加了重置功能,可将图例选项重置为默认值
- 水平、垂直和矩形图例形状