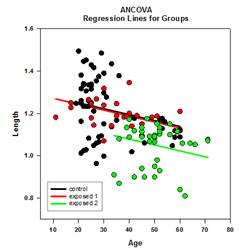
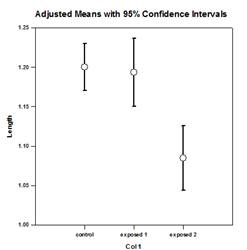
- Parcelas forestales
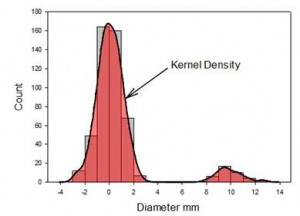
- Gráficos de densidad del núcleo
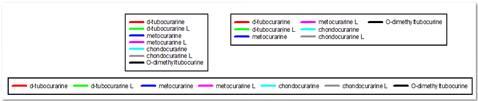
- 10 nuevas combinaciones de colores
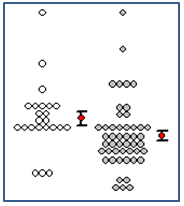
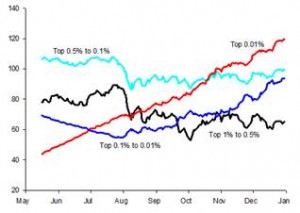
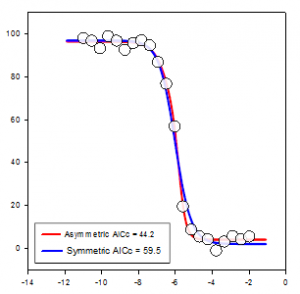
- Gráfico de densidad de puntos con barras de error medio y estándar
- Leyenda Mejoras
- Leyendas horizontales, verticales y rectangulares
- Cursor sobre lateral o asa superior o inferior

-
- permite leyendas de varias columnas
-
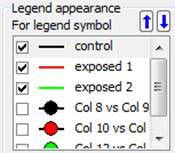
- Interfaz de usuario para establecer el número de columnas de elementos de leyenda en el cuadro de diálogo Propiedades. Los números de columna permitidos se muestran en la lista combinada
- Cambie el número de columnas de la leyenda seleccionando y arrastrando el asa central del cuadro delimitador.
- Reordenar los elementos de la leyenda
- A través del cuadro de diálogo de propiedades: desplace uno o varios elementos de la leyenda hacia arriba o hacia abajo mediante el control arriba/abajo situado en la parte superior del cuadro de lista.
- Mediante el movimiento del cursor: desplaza uno o varios elementos de la leyenda hacia arriba o hacia abajo. Seleccione el elemento o elementos de la leyenda y utilice las flechas arriba y abajo del teclado para desplazarse por el cuadro delimitador.
- Mediante la selección con el ratón y el movimiento del cursor de los elementos del cuadro delimitador
- Ajustes de las propiedades de los elementos individuales de la leyenda: seleccione elementos individuales de la leyenda y utilice la minibarra de herramientas para cambiar las propiedades.
- Control de la región en blanco del cuadro de leyenda mediante el cursor
- Cursor sobre asa de esquina

- permite un redimensionamiento proporcional
- Añadir etiquetado directo sencillo
- Admite «Etiquetado directo» en el cuadro de diálogo de propiedades mediante el control de casilla de verificación «Etiquetado directo».
- Desagrupar los elementos de la leyenda: los elementos individuales de la leyenda pueden desplazarse a las ubicaciones preferidas y moverse junto con el gráfico.
- Se ha añadido soporte para Leyenda Título (sin título por defecto). El usuario puede añadir un título al cuadro de leyenda utilizando el panel de propiedades de la leyenda
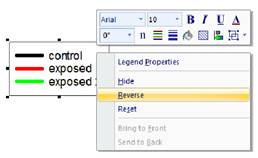
- Invertir los elementos de la leyenda mediante el menú contextual del botón derecho del ratón
- Para abrir las Propiedades de la Leyenda, haga doble clic en Leyenda Sólida o Leyenda Texto.
- Se ha añadido Restablecer a las leyendas para restablecer las opciones de leyenda a los valores predeterminados.
- Leyendas horizontales, verticales y rectangulares