It is tempting to think that these lines form a confidence band for the entire line. That is not true. The problem is that the upper and lower confidence limits are calculated by using one point at a time. In order to calculate a confidence band or interval for an entire line, we need to take into account the fact that two parameters, the constant and the coefficient of X, are being calculated for that line. Therefore, upper and lower confidence bands for the entire line would be given by:
BASIC
LET n=48
LET nvars=2
LET upperband = estimate+SQRT(2*FIF(.95,2,n-nvars))*sepred
LET lowerband = estimate+SQRT(2*FIF(.95,2,n-nvars))*sepred
PRINT upperband lowerband
RUN
 When you plot the confidence intervals for the estimated values of CANCER and the confidence bands for the regression line, you’ll see that the confidence band is wider than the confidence interval:
BEGIN
PLOT cancer*x(1) / SIZE=0 SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 ,
XMIN=100 XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upper,lower*x(1) /SIZE=0 SMOOTH=SPLINE SHORT YMIN=100,
YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=RED OVERLAY
PLOT upperband,lowerband*x(1) /SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
When you plot the confidence intervals for the estimated values of CANCER and the confidence bands for the regression line, you’ll see that the confidence band is wider than the confidence interval:
BEGIN
PLOT cancer*x(1) / SIZE=0 SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 ,
XMIN=100 XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upper,lower*x(1) /SIZE=0 SMOOTH=SPLINE SHORT YMIN=100,
YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=RED OVERLAY
PLOT upperband,lowerband*x(1) /SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
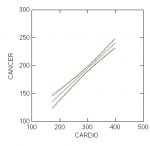 When you plot the confidence intervals for the estimated values of CANCER and the confidence bands for the regression line, you’ll see that the confidence band is wider than the confidence interval:
BEGIN
PLOT cancer*x(1) / SIZE=0 SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 ,
XMIN=100 XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upper,lower*x(1) /SIZE=0 SMOOTH=SPLINE SHORT YMIN=100,
YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=RED OVERLAY
PLOT upperband,lowerband*x(1) /SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
When you plot the confidence intervals for the estimated values of CANCER and the confidence bands for the regression line, you’ll see that the confidence band is wider than the confidence interval:
BEGIN
PLOT cancer*x(1) / SIZE=0 SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 ,
XMIN=100 XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upper,lower*x(1) /SIZE=0 SMOOTH=SPLINE SHORT YMIN=100,
YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=RED OVERLAY
PLOT upperband,lowerband*x(1) /SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
Because the relationship of CANCER (deaths per 100000 due to cancer) and CARDIO (deaths per 100000 due to cardiovascular disease) is linear, the difference between the confidence intervals for estimated values of CANCER and the confidence bands for the regression line is small, but even with well behaved data such as this the difference is apparent.
Second, it is also tempting to think that 95% of all of the observations should fall within the confidence bands. This is also not true. These are confidence bands for the mean only. If you wish to find confidence bands for observations, you must modify the calculation as you see below.
BASIC
LET n=48
LET nvars=2
LET s_square=177.065
LET upperband = estimate+TIF(.975,n-nvars)*SQR(sepred^2+s_square)
LET lowerband = estimate-TIF(.975,n-nvars)*SQR(sepred^2+s_square)
PRINT upperband lowerband
RUN
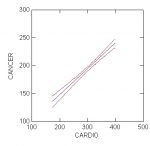
where S_SQUARE is the mean square residual from the regression. These are sometimes called prediction intervals. When entering your values for N and NVARS, also enter the value for S_SQUARE, which you will find in the Analysis of Variance table of the regression output.
Now, if you wish to see the results of this calculation, issue the following command sequence:
BEGIN
PLOT cancer*x(1) /SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 XMIN=100,
XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upperband,lowerband*x(1) / SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
This will plot the confidence bands or prediction intervals around the data.
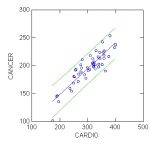 BEGIN
PLOT cancer*x(1) /SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 XMIN=100,
XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upperband,lowerband*x(1) / SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
This will plot the confidence bands or prediction intervals around the data.
BEGIN
PLOT cancer*x(1) /SMOOTH=LINEAR SHORT YMIN=100 YMAX=300 XMIN=100,
XMAX=500 XLABEL=’CARDIO’ COLOR=BLUE
PLOT upperband,lowerband*x(1) / SIZE=0 SMOOTH=SPLINE SHORT,
YMIN=100 YMAX=300 XMIN=100 XMAX=500 YLABEL=’ ‘,
XLABEL=’ ‘ COLOR=GREEN OVERLAY
END
This will plot the confidence bands or prediction intervals around the data.