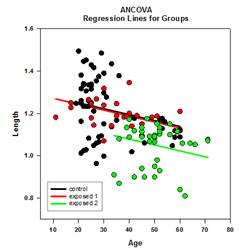
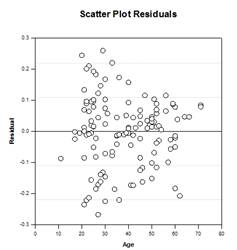
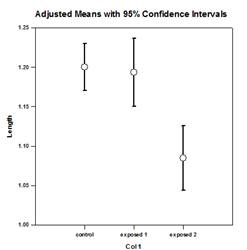
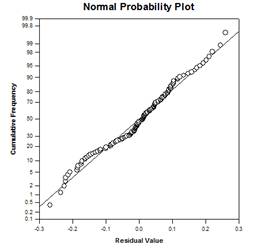
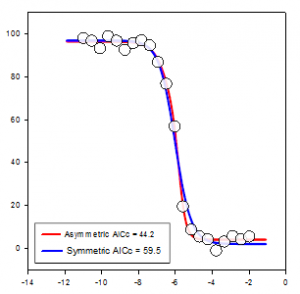
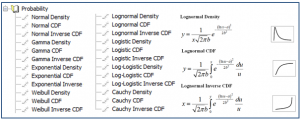
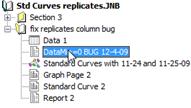
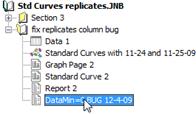
- Parcelles forestières
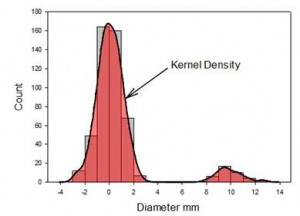
- Graphiques de densité du noyau
- 10 nouvelles gammes de couleurs
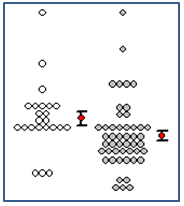
- Graphique de densité de points avec barres de moyenne et d’erreur standard
- Légende Améliorations
- Formes de légende horizontales, verticales et rectangulaires
- Curseur sur le côté ou sur la poignée supérieure ou inférieure

-
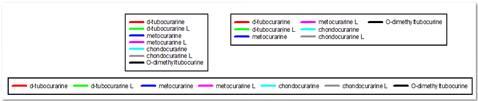
- permet des légendes à plusieurs colonnes
-
- Interface utilisateur permettant de définir le nombre de colonnes de l’élément de légende dans la boîte de dialogue Propriétés. Les numéros de colonne autorisés sont affichés dans la liste déroulante
- Modifier le nombre de colonnes de l’élément de légende en sélectionnant et en faisant glisser la poignée du milieu dans la boîte de délimitation.
- Réorganiser les éléments de la légende
- Dans la boîte de dialogue des propriétés – déplacer un ou plusieurs éléments de la légende vers le haut ou vers le bas à l’aide du contrôle haut/bas situé en haut de la zone de liste.
- Par le déplacement du curseur – déplacer un ou plusieurs éléments de la légende vers le haut ou vers le bas. Sélectionnez le(s) élément(s) de la légende et utilisez les touches fléchées haut et bas du clavier pour vous déplacer à l’intérieur de la boîte de délimitation.
- Sélection à l’aide de la souris et déplacement du curseur pour les éléments situés dans la boîte englobante
- Paramètres des propriétés des éléments de légende individuels – sélectionnez des éléments de légende individuels et utilisez la mini-barre d’outils pour modifier les propriétés.
- Contrôle de la région vide de la boîte de légende à l’aide du curseur
- Curseur sur la poignée d’angle

- permet un redimensionnement proportionnel
- Ajouter un étiquetage direct simple
- Prise en charge de l’étiquetage direct dans la boîte de dialogue des propriétés à l’aide de la case à cocher “Étiquetage direct”.
- Dégrouper les éléments de la légende – les éléments individuels de la légende peuvent être déplacés vers des emplacements préférés et se déplacer en même temps que le graphique.
- La prise en charge du titre de la légende a été ajoutée (pas de titre par défaut). L’utilisateur peut ajouter un titre à la boîte de légende à l’aide du panneau des propriétés de la légende
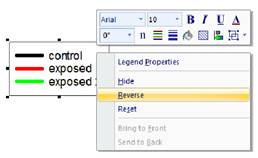
- Inverser les éléments de la légende à l’aide du menu contextuel du clic droit
- Ouvrez les propriétés de la légende en double-cliquant sur Légende solide ou Légende texte.
- L’option Réinitialiser a été ajoutée aux légendes pour réinitialiser les options de légende par défaut.
- Formes de légende horizontales, verticales et rectangulaires