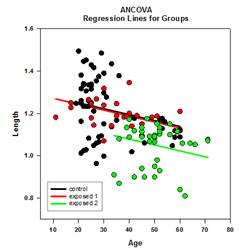
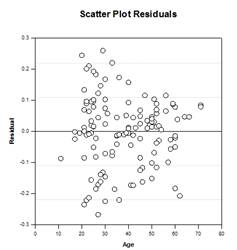
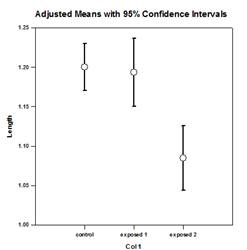
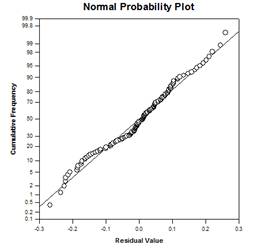
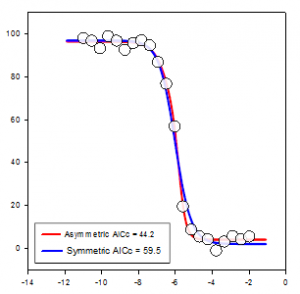
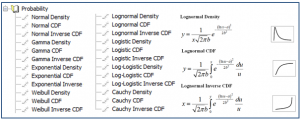
- 森林圃場
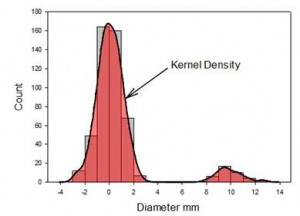
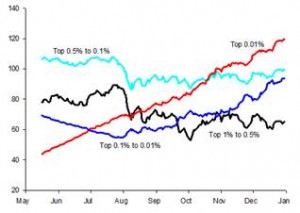
- カーネル密度プロット
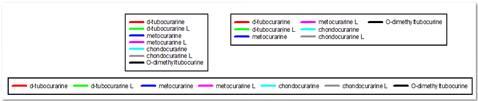
- 10の新しい配色
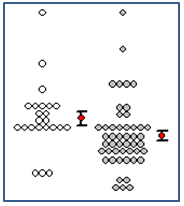
- ドット密度グラフ(平均値と標準誤差バー付き
- レジェンドの改善
- 水平、垂直、長方形の凡例図形
- カーソルをサイドまたは上下のハンドルに合わせる

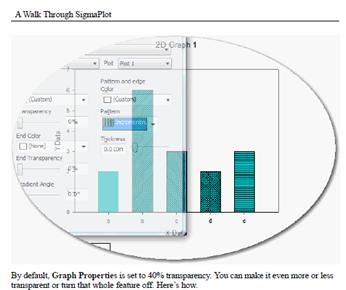
-
- 複数列の凡例が可能
-
- プロパティダイアログで凡例項目の列数を設定するユーザーインターフェイス。 許容される列番号はコンボリストに表示される。
- バウンディング・ボックスの真ん中のハンドルを選択しドラッグして、凡例項目の列数を変更する。
- 凡例項目の並び替え
- プロパティダイアログを通して – リストボックスの上部にある上下コントロールを使用して、1つまたは複数の凡例項目を上下に移動する。
- カーソルの移動により、1つまたは複数の凡例項目を上下に移動する。 凡例項目を選択し、キーボードの上下矢印キーでバウンディングボックス内を移動する。
- バウンディング・ボックス内のアイテムをマウスで選択し、カーソルを動かす。
- 個々の凡例項目のプロパティ設定 – 個々の凡例項目を選択し、ミニツールバーを使用してプロパティを変更する。
- カーソルでレジェンドボックスの空白領域をコントロール
- カーソルをコーナーハンドルに合わせる

- プロポーショナル・リサイズが可能
- シンプルなダイレクト・ラベルの追加
- プロパティ・ダイアログで、”ダイレクト・ラベリング “チェックボックス・コントロールを使用して、”ダイレクト・ラベリング “をサポートする。
- 凡例アイテムのグループ解除 – 個々の凡例アイテムを好きな場所に移動し、グラフと連動して移動することができます。
- 凡例タイトルのサポートが追加されました(デフォルトではタイトルなし)。 ユーザーは、凡例プロパティパネルを使用して、凡例ボックスにタイトルを追加できます。
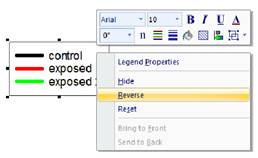
- 右クリックのコンテキストメニューを使用して、凡例項目を反転させる。
- 凡例ソリッドまたは凡例テキストのいずれかをダブルクリックして、凡例プロパティを開きます。
- 凡例にリセットが追加され、凡例オプションがデフォルトにリセットされます。
- 水平、垂直、長方形の凡例図形